线性表
数组
数组是存放在连续内存空间上的相同类型数据的集合。
举一个字符数组的例子,如图所示: 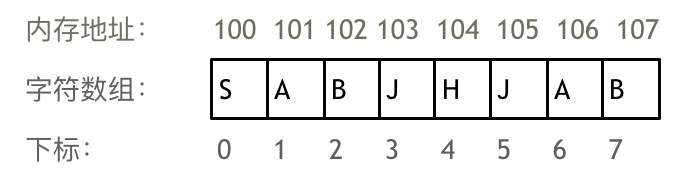
需要两点注意的是
- 数组下标都是从 0 开始的。
- 数组内存空间的地址是连续的
正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
那么二维数组在内存的空间地址是连续的么? 不同编程语言的内存管理是不一样的,以 C++为例,在 C++中二维数组是连续分布的。
一维数组
二维数组
字符串基础
字符串匹配
KMP
KMP 是非常简短巧妙的字符串匹配算法,它利用 part 字符串自身前后缀信息,处理出 next 数组(一段字符串中前缀字符串和后缀字符串相同的最大长度)
再根据 next 数组, 优化暴力算法匹配失败字符串移动的步骤
时间复杂度:
#include <iostream>
using namespace std;
const int N = 1e5 + 5, M = 1e6 + 5;
int ne[N];
char p[N], s[M];
int n, m;
int main(){
cin >> n >> p + 1 >> m >> s + 1;
// 求解 next 数组,具体的含义是 p 字符串 从某处开始, 前缀和后缀字符串相同的最大长度
// 思路和匹配部分一样,不过求 next 数组需要使用 p 自己和自己匹配
for (int i = 2, j = 0; i <= n; i ++) { // [2, n] , 因为 next[1] = 0, 可以跳过
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++;
ne[i] = j; // 这里不用考虑是否整段匹配完,只要匹配成功,j 即是最长的距离
}
// 匹配
for (int i = 1, j = 0; i <= m; i ++){ // 注意是 [1, m]
while (j && p[j + 1] != s[i]) j = ne[j]; // 如果在 i(j+1) 处匹配失败,由于next数组的存在,可以移动最大的长度重新匹配
if (p[j + 1] == s[i]) j ++; // 移动若干次,如果能匹配,则继续匹配下一个字符
if (j == n) printf("%d ", i - n); // 整段 part 都匹配完成,返回 subPart 的下标,j 继续回退进行下一次匹配
// j = ne[j] 可以省略不写
}
return 0;
}
字典树(Trie)
Trie 树是一种能高效存储查询字符串的数据结构, 本质上只是多叉树
#include <iostream>
using namespace std;
const int N = 1e5 + 5;
int son[N][26], idx, cnt[N];
char str[N];
void insert(char str[]){
int p = 0;
for (int i = 0; str[i]; i ++){
int u = str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx; // 如果结点没有该字母分支,则创建分支
p = son[p][u]; // 进入分支
}
cnt[p] ++; // 在最后的位置插入数加一
}
int query(char str[]){
int p = 0;
for (int i = 0; str[i]; i ++){
int u = str[i] - 'a';
if (!son[p][u]) return 0; // 如果结点没有该字母分支,直接返回0,即没有储存该字符串
p = son[p][u];
}
return cnt[p]; // 返回在该处插入数
}
int main(){
int n;
cin >> n;
while (n --){
char op[2];
scanf("%s%s", op, str);
if (op[0] == 'I') insert(str);
else printf("%d\n", query(str));
}
return 0;
}
idx 是节点的编号,相当于唯一的地址,son 数组相当于邻接矩阵,储存的是整棵 trie 树
TIP
son 等于 0 表示的意义是没有存放字母
最大异或对
#include <iostream>
using namespace std;
const int N = 1e5 + 5, M = 31 * N;
int son[M][2], a[N], idx;
void insert(int x){
int p = 0;
for (int i = 30; ~i ; i --){ // 直接写 i, 表示 i != 0 又因为 ~0 = -1 则 ~i 表示 i != -1, 即[30, 0]
int &s = son[p][x >> i & 1];
if (!s) s = ++ idx;
p = s;
}
}
int query(int x){
int p = 0, res = 0;
for (int i = 30; ~i; i --){
int s = x >> i & 1;
if (son[p][!s]){
res += 1 << i;
p = son[p][!s];
}
else p = son[p][s];
}
return res;
}
int main(){
int n;
cin >> n;
for (int i = 0; i < n; i ++)
cin >> a[i], insert(a[i]);
int res = 0;
for (int i = 0; i < n; i ++)
res = max(res, query(a[i]));
cout << res << endl;
return 0;
}
链表
单链表
什么是链表,链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向 null(空指针的意思)。
链接的入口节点称为链表的头结点也就是 head。
如图所示: 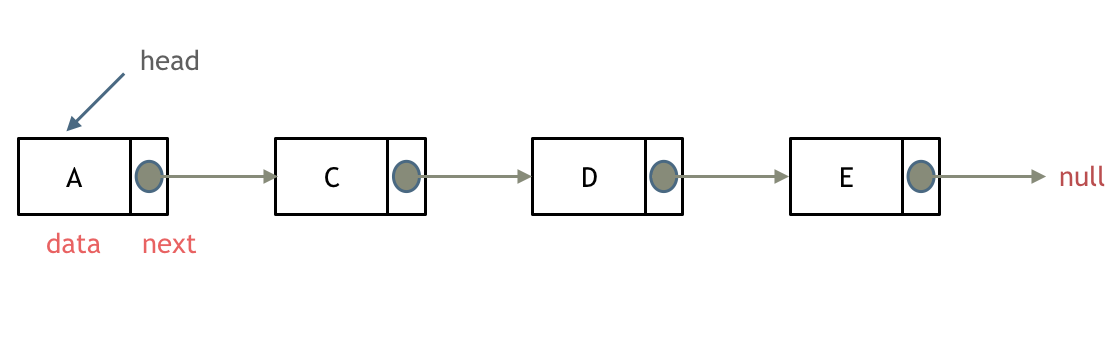
双链表
单链表中的指针域只能指向节点的下一个节点。
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。
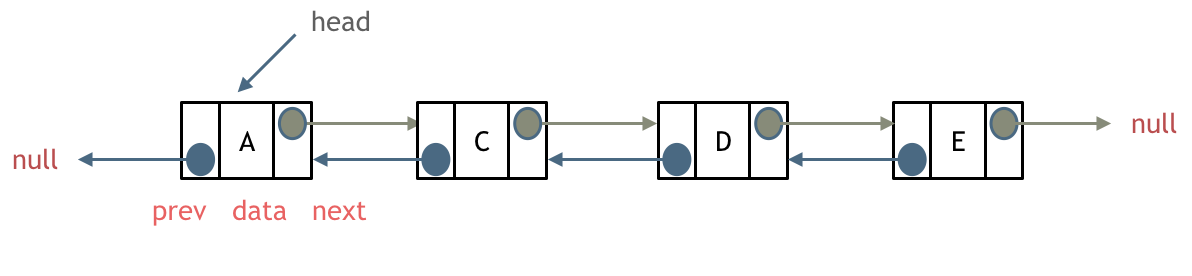
循环链表
循环链表,顾名思义,就是链表首尾相连。
循环链表可以用来解决约瑟夫环问题。 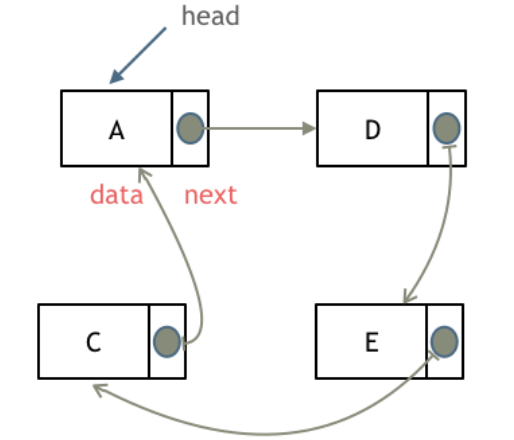
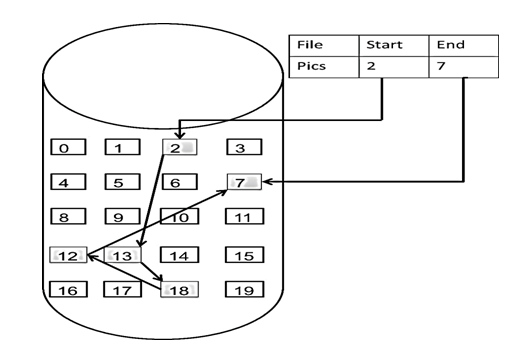
链表的存储方式
了解完链表的类型,再来说一说链表在内存中的存储方式。
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图所示:
删除节点
删除 D 节点,如图所示: 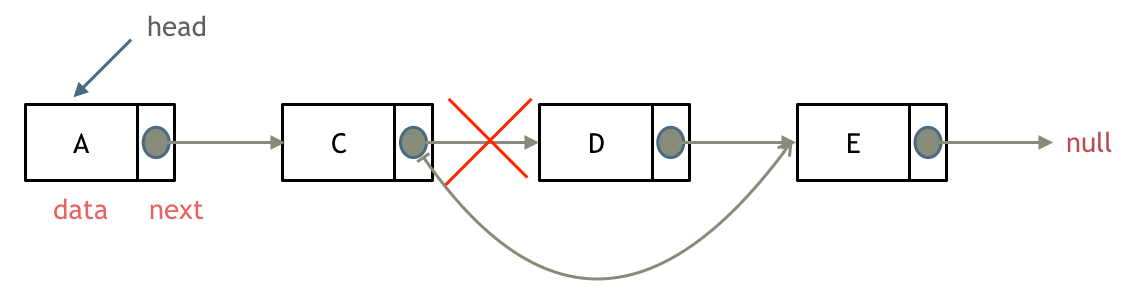
在 C++里最好是再手动释放这个 D 节点,释放这块内存。
其他语言例如 Java、Python,就有自己的内存回收机制,就不用自己手动释放。
203.移除链表元素
我最开始想到的是双指针,pre 指向 now, 方便删除,可是如果用最笨的方法会遍历, 优化的写法也很麻烦。
但其实可以把p.Next作为now, p 作为pre, 这样pre 永远指向 now, 而且只需要遍历链表一次, 因此时间复杂度只有
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func removeElements(head *ListNode, val int) *ListNode {
if head == nil {return nil}
newhead := &ListNode{Next:head}
for p := newhead; p.Next != nil; {
if p.Next.Val == val {
p.Next = p.Next.Next
} else {
p = p.Next
}
}
return newhead.Next
}
添加节点
如图所示:
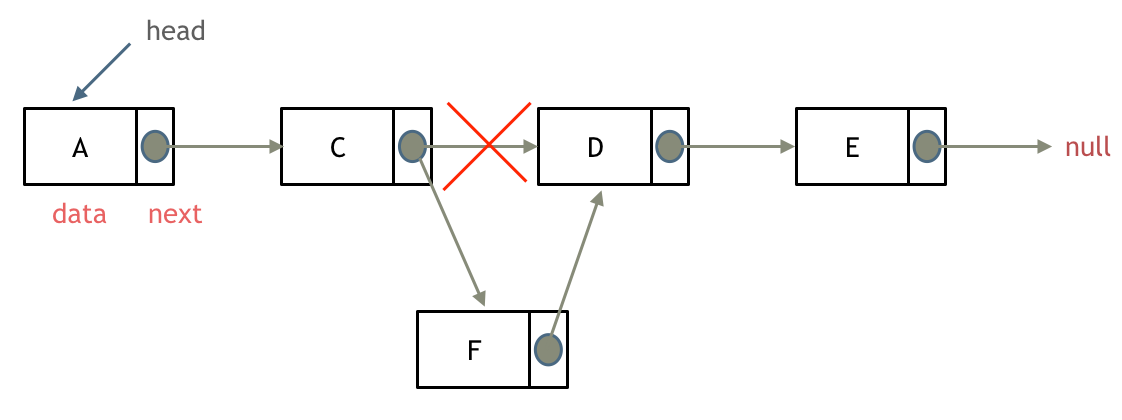
可以看出链表的增添和删除都是 操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过 next 指针进行删除操作,查找的时间复杂度是 。
性能分析
再把链表的特性和数组的特性进行一个对比,如图所示: 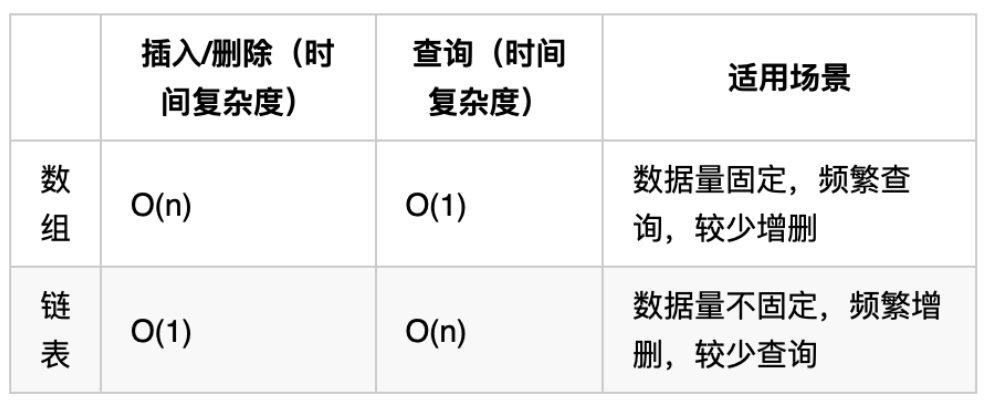
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
单链表设计
节点只有 val 和 next 两个属性
一般单链表使用一个空的头节点,也可以使用尾节点优化尾插,但是最常用还是一个头节点
type Node struct {
Val int
Next *Node
}
type MyLinkedList struct {
head *Node
Count int
}
func Constructor() MyLinkedList {
return MyLinkedList{head: &Node{}}
}
func (this *MyLinkedList) Get(index int) int {
if this.Count == 0 || index < 0 || index >= this.Count {
return -1
}
p := this.head.Next
for i := 0; i < index; i, p = i + 1, p.Next {}
return p.Val
}
func (this *MyLinkedList) AddAtHead(val int) {
p := &Node{Val:val}
p.Next = this.head.Next
this.head.Next = p
this.Count ++
}
func (this *MyLinkedList) AddAtTail(val int) {
tail := this.head.Next
if tail == nil {
this.AddAtHead(val)
return
}
for ; tail.Next != nil; tail = tail.Next {}
p := &Node{Val:val}
tail.Next = p
this.Count ++
}
func (this *MyLinkedList) AddAtIndex(index int, val int) {
if index == this.Count {
this.AddAtTail(val)
return
}
if index <= 0 {
this.AddAtHead(val)
return
}
if index > this.Count {
return
}
p := &Node{Val: val}
pre := this.head
for ;index > 0; index -- {
pre = pre.Next
}
p.Next = pre.Next
pre.Next = p
this.Count ++
}
func (this *MyLinkedList) DeleteAtIndex(index int) {
if index < 0 || index >= this.Count {
return
}
pre := this.head
for ; index > 0; index -- {
pre = pre.Next
}
pre.Next = pre.Next.Next
this.Count --
}
/**
* Your MyLinkedList object will be instantiated and called as such:
* obj := Constructor();
* param_1 := obj.Get(index);
* obj.AddAtHead(val);
* obj.AddAtTail(val);
* obj.AddAtIndex(index,val);
* obj.DeleteAtIndex(index);
*/
双向链表设计
一个节点,有 val, left, right 三个属性
与单向链表的区别,双向链表可以前后遍历,因此需要头尾节点
type Node struct {
Val int
Left *Node
Right *Node
}
type MyLinkedList struct {
head *Node
tail *Node
Count int
}
func Constructor() MyLinkedList {
head, tail := &Node{Val: -1}, &Node{Val: -1}
head.Right = tail
tail.Left = head
return MyLinkedList{head: head, tail: tail}
}
func (this *MyLinkedList) Get(index int) int {
if this.Count == 0 || index < 0 || index >= this.Count {
return -1
}
p := this.head.Right
for ; index > 0; index -- {
p = p.Right
}
return p.Val
}
func (this *MyLinkedList) AddAtHead(val int) {
p := &Node{Val: val}
p.Right = this.head.Right
p.Left = this.head
this.head.Right.Left = p
this.head.Right = p
this.Count ++
}
func (this *MyLinkedList) AddAtTail(val int) {
p := &Node{Val: val}
p.Left = this.tail.Left
p.Right = this.tail
this.tail.Left.Right = p
this.tail.Left = p
this.Count ++
}
func (this *MyLinkedList) AddAtIndex(index int, val int) {
if index > this.Count {return}
if index == this.Count {
this.AddAtTail(val)
return
}
if index <= 0 {
this.AddAtHead(val)
return
}
p := &Node{Val: val}
pre := this.head
for ; index > 0; index -- {
pre = pre.Right
}
p.Left = pre
p.Right = pre.Right
pre.Right.Left = p
pre.Right = p
this.Count ++
}
func (this *MyLinkedList) DeleteAtIndex(index int) {
if this.Count == 0 || index < 0 || index >= this.Count {
return
}
p := this.head
for ; index > 0; index -- {
p = p.Right
}
p.Right.Right.Left = p
p.Right = p.Right.Right
this.Count --
}
/**
* Your MyLinkedList object will be instantiated and called as such:
* obj := Constructor();
* param_1 := obj.Get(index);
* obj.AddAtHead(val);
* obj.AddAtTail(val);
* obj.AddAtIndex(index,val);
* obj.DeleteAtIndex(index);
*/
栈
后入先出,是栈(stack)的特点, 就像一个筒,只能先拿最靠近口元素
需要注意的是,栈顶一般指向最后那个元素
中缀表达式求值,可以使用栈来模拟递归运行的过程
#include <iostream>
#include <stack>
#include <unordered_map>
using namespace std;
stack<int> num;
stack<char> op;
void eval(){
int b = num.top();num.pop();
int a = num.top();num.pop();
char ope = op.top();op.pop();
int x;
if (ope == '+') x = a + b;
else if (ope == '-') x = a - b;
else if (ope == '*') x = a * b;
else x = a / b;
num.push(x);
}
int main(){
string str;
cin >> str;
unordered_map<char, int> pr{{'+', 1}, {'-', 1}, {'*', 2}, {'/', 2}};
for (int i = 0; i < str.size(); i ++){
auto c = str[i];
if (isdigit(c)){
int x = 0, j = i;
while (j < str.size() && isdigit(str[j]))
x = x * 10 + str[j ++] - '0';
i = j - 1;
num.push(x);
} else if (c == '(') op.push(c);
else if (c == ')'){
while (op.top() != '(') eval(); // 读到 ) 需要先把之前的运算先处理
op.pop(); // 再把 ( 弹出
} else {
while (op.size() && op.top() != '(' && pr[op.top()] >= pr[c]) eval();
// 如果栈中已经存在一个符号,并且它是运算符号,那么如果它的优先级比当前的高或相同(由于它先入栈所以也要优先考虑)那么先计算它, 再把当前符号入栈(符号入栈的顺序由优先级决定)
op.push(c);
// 如果这符号栈为空 或 栈顶的符号优先级比当前的低,那么先计算当前符号,则直接入栈
}
}
while (op.size()) eval();
cout << num.top() << endl;
return 0;
}
单调栈
单调栈需要保持栈内的元素的单调性
- 如果 push 当前元素能保持栈的单调性,则放入元素
- 如果不行则不停地弹出元素,直到 push 当前元素后仍能保持单调性
#include <iostream>
using namespace std;
const int N = 1e5 + 5;
int stack[N], tt = -1;
int main(){
int n;
cin >> n;
while (n --){
int x;
cin >> x;
while (tt != -1 && stack[tt] >= x) tt --;
if (tt == -1) cout << -1 << ' ';
else cout << stack[tt] << ' ';
stack[++ tt] = x;
}
return 0;
}
队列
队列(queue)与栈正好相反,先进先出
需要注意的是,当队头指针大于尾指针时,队列才为空,它们相等时说明还存在一个元素(t - h + 1)
单调队列
与单调栈类似,时刻维持队列中的单调性
如果如果加入某个元素无法保证单调性,则先 pop 影响的元素再加入这个元素
维护单调性的好处是可以在O(1) 内找到队列的最大最小值,或者最接近某个元素的值
#include <iostream>
using namespace std;
const int N = 1e6+5;
int a[N], q[N];
int n, k;
int main(){
cin >> n >> k;
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++){
scanf("%d", &a[i]);
if (hh <= tt && i - k + 1 > q[hh]) hh ++; // q 存放的是 下标, 这句表示窗口需要右移动了
while (hh <= tt && a[i] <= a[q[tt]]) tt --; // a[i] <= a[q[tt]] 等号也把队尾t出,可以保证队列严格单调
q[++ tt] = i;
if (i >= k - 1)
printf("%d ", a[q[hh]]); // 窗口长度小于 k 时不输出
}
cout << endl;
hh = 0, tt = -1;
for (int i = 0; i < n; i ++){
if (hh <= tt && i - k + 1> q[hh]) hh ++;
while (hh <= tt && a[i] >= a[q[tt]]) tt --;
q[++ tt] = i;
if (i >= k - 1)
printf("%d ", a[q[hh]]);
}
return 0;
}