传统的 Website
maybe,一些简短的常见概念 •﹏•
Client/Server
常说的 C/S 就是指 client 与 server
Client 一般可以分为:
- Browser
- Other Apps, eg: curl
Server 一般可以分为:
- Web Server
- Application Server
C/S 之间的联系
客户端是使用/消费服务端实体
A Client is an entity that consumes a Server.
服务端是服务客户端的实体
A Server is an entity that serves a Client.
两者的概念是相对的,相辅相成,可以说没有客户端就没有服务端,没有服务端就没有客户端。
通讯
举一个常见的例子来说:
当使用浏览器上网时:
- 输入 url,访问。
- 浏览器向该 url 指代的 web 服务端发送 http 请求。
- 如果请求没有错误,服务端返回资源给浏览器。
- 浏览器展示资源给用户。

这里的 http 是客户端与服务端的通讯协议,且是 web 最常用的通讯协议。
TIP
可以发现,上个例子中的 client 具体指代的就是 browser,而它请求的资源是 html,响应它请求的 server 就是 web server。
HTTP
其实 http 也是广义上的 rpc 协议,大家习惯上把狭义上的 rpc 协议与 http 区分开。
Remote procedure call 远程过程调用
详细的 http 知识不展开,下面是 HTTP 常用的请求方式:
GET:用于请求静态资源。POST:用于上传数据或静态资源,非幂等的。PUT:用于更新资源或数据,是幂等的。DELETE:用于删除资源或数据。
这些请求方式通常是带有语义的,他们负责的职能就是常见的CRUD操作。
TIP
幂等是数学的一个用语,对于单个输入或者无输入的运算方法,如果每次都是同样的结果,则称其是幂等的。也就是说,如果一个网络重复执行多次,产生的效果是一样的,那就是幂等(idempotent)
是不是幂等很重要吗,我查到的概念,第一次听说。💩
Client
Client 指客户端,运行在用户侧,通过网络请求向服务端获取/更改信息,并把结果展示给用户。
Client,可以指 Browser、curl、wget、postman、安卓程序以及桌面程序,它指代一切能发送请求与服务端通信的应用。
在 Web 里说的 client 很多情况下指的就是 browser,但是也不是绝对的。 比如说,在分布式系统里,不同的 server 需要调用彼此之间的接口(函数)时,需要向对方发起请求,那么这时的 server 充当了 client 的角色。
Server
Web Server 与 Application Server 的不同
Web Server
Web Server 一般用以响应 client 请求的静态资源(eg: HTML, CSS, JS, etc),这些资源可以轻松地通过 Http 协议传输。静态资源在 server 上是以文件的方式存在的,而传输到 browser 可以被识别渲染成页面展示给用户。
常见的 web server 有 nginx, apache,caddy 等等
Application Server
application server 的服务远超出静态文件,比如 JSON 格式的数据。
你会发现 Http 的 通信是同步的,即 client 发送一次请求,必须要等到 server 返回信息,才能发送下一条,那么 application server 还能使用 WebSocket 等协议来解决双向通信的同步问题,更重要的是 application server 可以使用不同的特定语言来编写。
Other Server
还有一些时候 Server 指代的不是软件应用,而是实体或云上的服务器。
- deploy: 部署,意味着把 server 应用运行在实体服务器上。
- host:托管,意味着让 server 应用持续地运行服务。
为什么 server 应用需要部署到服务器呢?
因为本地上运行的服务端,只能本地用户通过本地 ip 组成的 url(eg: localhost)访问,如果想要让互联网上的所有人都能访问你的网站,那么需要把 server 应用部署到公网的服务器上,这样才能让其他人通过公网的 ip 组成的 url 访问到你的网站。
或者让本地成为服务器,即把本地机器暴露到公网。
URL
URL 代表着是统一资源定位符(Uniform Resource Locator),它是浏览器用来检索 web 上公布的任何资源的机制,就是一个给定的独特资源在 Web 上的地址。
URL 的路径
一般来说,在浏览器里,不同的 url path 代表了不同的页面(page)或路由(route)。
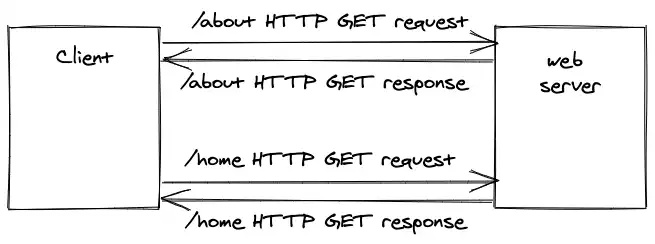
如果访问 /about 那么 about 页面会被 server 响应给 browser,访问/home server 就会把 home 页面响应给 browser,由 server 来决定不同 url path 响应什么资源的过程就叫做 服务端渲染 SSR(server-side-rendering),与之对应的还有 CSR(client-side-rendering)
HTML URL 请求其他资源
现代的网站由 html(structure)、css(style)、javascript(logic)组成,没有 css,网站的页面或许无法正确被显示;没有 js 网站将失去动态的交互;css 和 js 一般被 linked 到 html 文件中。
<link href="/media/examples/link-element-example.css" rel="stylesheet" />
<h1>Home at /home route</h1>
<p class="danger">Red text as defined in the external CSS file.</p>
当用户向 server 请求 html 的 url 时,server 会返回对应的 html 文件,如果该文件中 linked 了 css 和 js 等静态资源,那么浏览器将再次发送请求去获取这些文件。

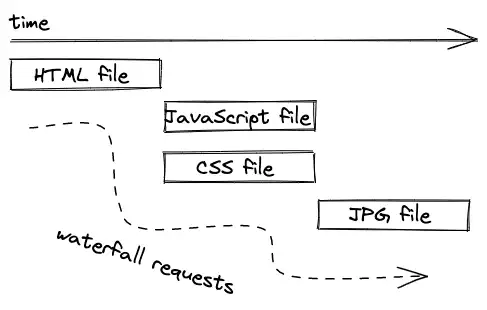
有一个名词称呼这个过程:请求瀑布( waterfall requests ),因为每一个请求必须等待前一个完成才能发送。
在我们的例子中,浏览器不知道要在 html 文件完成加载之前请求 css,如果 html 中 linked 了 css,而 css 中又包含了 jpg 图片(用作背景图片),那么请求应该会变成以下的样子:
幸好,如果很多个文件引用在同一个文件中被定义的话,那么这些请求会被平行发送。
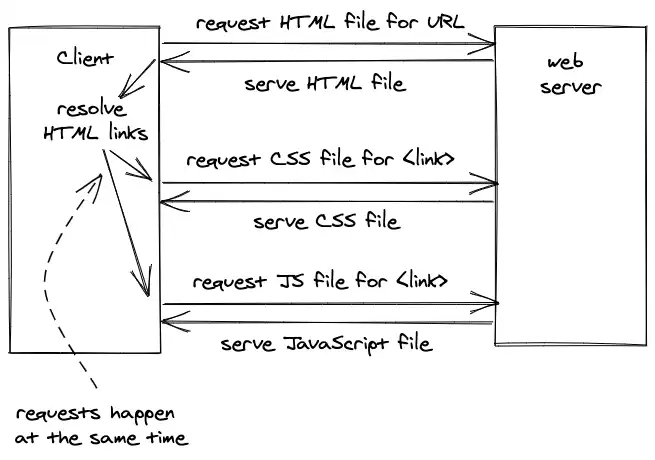
最终,浏览器获得了所有的资源,并把原来 url 对应的 html 内容 与它所包含的文件一并渲染出来,用户就可以看到网页了。